这里是两台服务器配置Redis集群,3主3从
在两台服务器都安装redis,然后配置不同的redis.C++onf配置文件,以不同的节点去启动redis
根据安装包类型进行安装,建议版本5以上,低版本需依赖Ruby环境,且部署步骤复杂
[](https://wwkv.lanzouw.com/iYf2d2ukw1ta 密码:2vtn)
上传安装包至/opt目录 选择自己想要的安装的目录也可以
cd /opt
tar -zxvf redis-4.0.11-16.p04.ky10.x86_64.rpm.tar.gz
rpm -ivh redis-4.0.11-16.p04.ky10.x86_64.rpm
tar -zxvf redis-5.0.1.tar.gz
make install make PREFIX=/app/redis install 也可以指定路径安装
systemctl daemom-reload //使得系统systemd的service文件重启生效,如果修改了service启动脚本
systemctl enable redis.service
systemctl start redis.service
常用的启动redis命令:
启动Redis服务:
systemctl start redis.service
停止Redis服务:
systemctl stop redis.service
重启Redis服务:
当修改了配置文件后,你可能需要重启Redis服务以使更改生效。
systemctl restart redis.service
查看Redis服务状态:
检查Redis服务是否正在运行。
systemctl status redis.service
启用开机自启动:
让Redis随系统启动自动运行。
systemctl enable redis.service
禁用开机自启动:
取消Redis随系统启动自动运行。
systemctl disable redis.service
两台机器互通 例如
182.18.31.91 182.18.31.92
3主3从 6379 6380 6381 6382 6383 6384
一台机器3个,创建3文件夹以区分对应节点端口配置
182.18.31.91中 92中同下述操作,只是配置文件的端口不一样
mkdir -p /usr/local/redis-cluster/
还需要建立以下文件夹
/usr/local/redis-cluster/6379/data 存放数据文件
/usr/local/redis-cluster/6379/log 存放日志
将配置文件复制不同目录下
cp redis.conf /usr/local/redis-cluster/6379/redis-6379.conf
cd /usr/local/redis-cluster/6379/
vi redis-6379.conf
**修改以下关键配置**
port 6379
bind 0.0.0.0
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-node-timeout 5000
appendonly yes
pidfile /var/run/redis_6379.pid
logfile /usr/local/redis-cluster/6379/log/redis.log
dir /usr/local/redis-cluster/6379/data #dir 存放数据文件,例如生成的nodes-6379.conf
redis-server redis-cli 在redis安装目录src里,启动每个实例
可以创建一个redis的systemd 的service脚本文件启动/停止/重启所有端口
./redis-server /usr/local/redis-cluster/6379/redis-6379.conf
./redis-server /usr/local/redis-cluster/6380/redis-6380.conf
./redis-server /usr/local/redis-cluster/6381/redis-6381.conf
./redis-server /usr/local/redis-cluster/6382/redis-6382.conf
./redis-server /usr/local/redis-cluster/6383/redis-6383.conf
./redis-server /usr/local/redis-cluster/6384/redis-6384.conf
或redis@service 多实例启动脚本文件
[Unit]
Description=Redis instance for port %i
After=network.target
[Service]
Type=Forking
PIDFile=/var/run/redis-%i.pid
User=redis
Group=redis
ExecStart=/usr/local/redis/redis-5.0.1/src/redis-server /usr/local/redis-cluster/%i/redis-%i.conf #修改redis目录
ExecStop=/usr/local/redis/redis-5.0.1/src/redis-cli -p %i shutdown
Restart=always
RestartSec=5s
PrivateTmp=true
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
systemctl daemon-reload //重新加载systemd服务
systemctl start redis@6379.service //根据端口号去启动不同的redis实例
systemctl status redis@6379.service
systemctl restart redis@6379.service
systemctl stop redis@6379.service
查看进程
ps -ef|grep redis
当所有实例都成功启动后,在任意一台服务器上使用redis-cli创建集群
redis-cli --cluster create 182.18.31.91:6379 182.18.31.91:6380 182.18.31.91:6381 182.18.31.92:6382 182.18.31.92:6383 182.18.31.92:6384 --cluster-replicas 1
// --cluster-replicas 1表示每个主节点有一个从节点
//Redis 4.0不支持--cluster选项
如何验证集群是否创建成功
启动 redis-cli 并进入集群模式:
你也可以直接使用redis-cli命令进入集群模式,然后执行集群相关的命令
redis-cli --cluster check 182.18.31.91:6379
其中host和port你想要连接的Redis集群节点的IP地址和端口
redis-cli -c -h host -p port
在 redis-cli 中执行集群命令:
cluster info //查看集群的信息
cluster nodes //查看集群中的节点列表
set hello world //后在get hello 查看获取的值是不是world
查看redis进程是否已切换为集群状态(cluster)
ps aux|grep redis
注意
“3 主 3 从” 是 Redis Cluster 的最小高可用配置,核心是满足哈希槽分配和多数派投票需求
1.至少需要 3 个 master 的原因
Redis Cluster 将 16384 个哈希槽分配给所有 master 节点,数据按槽存储。而故障转移的前提是 “多数派投票”:当某个 master 宕机时,其 slave 要晋升为新 master,需要获得超过半数的其他 master 节点同意(即 “quorum” 机制)。
若只有 2 个 master:假设 master1 宕机,仅剩 master2,此时无法获得 “超过半数”(2 个节点需至少 2 票同意,但仅剩 1 个 master,无法满足),故障转移失败。
若有 3 个 master:即使 1 个 master 宕机,剩余 2 个 master,2 > 3/2(多数),可正常投票让 slave 晋升,保证集群可用。
因此,Redis Cluster 强制要求至少 3 个 master 才能正常工作(少于 3 个无法完成哈希槽分配和故障转移)。
2.每个 master 配 1 个 slave(3 主 3 从)的原因
每个 master 需要至少 1 个 slave 来保证:
数据冗余:slave 通过异步复制同步 master 数据,避免 master 宕机导致数据丢失。
故障接管:当 master 宕机时,其 slave 可通过投票晋升为新 master,继续提供服务。
3 主 3 从(共 6 节点)是最小高可用配置,通常会分散在不同服务器(如 3 台服务器,每台 1 主 1 从),避免单服务器宕机导致 “主从同挂”。
如果 3 个 master 集中在同一台服务器,该服务器宕机后:
若这 3 个 master 的 slave 在其他服务器(且存活),但此时原 3 个 master 已下线,剩余的 master 数量为 0(无法满足多数派投票),集群会进入 “不可用” 状态,自动故障转移失败,必须手动干预
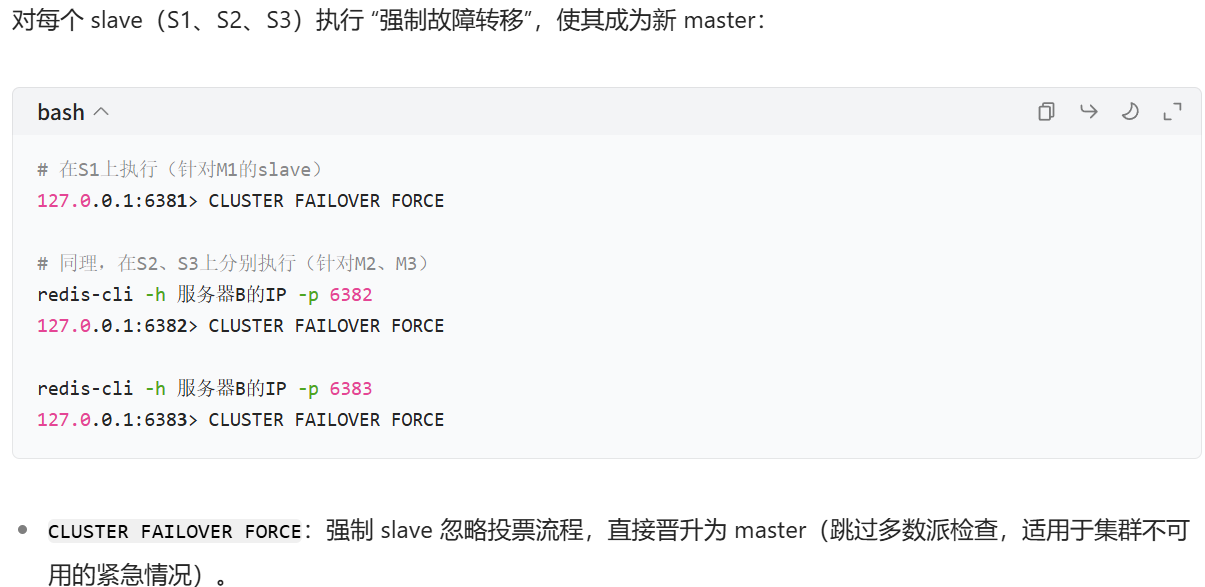
查看槽位分配情况(应显示所有16384个槽已分配)
127.0.0.1:6381> cluster info | grep cluster_state
若输出“cluster_state:ok”,表示集群恢复可用