该mysql不是指mysql服务,而是指mysql的客户端工具。
语法 :
mysql [options] [database]
参数 :
-u, --user=name 指定用户名
-p, --password[=name] 指定密码
-h, --host=name 指定服务器IP或域名
-P, --port=# 指定连接端口
示例 :
mysql -h 127.0.0.1 -P 3306 -u root -p
mysql -h127.0.0.1 -P3306 -uroot -p2143
-e, --execute=name 执行SQL语句并退出
此选项可以在Mysql客户端执行SQL语句,而不用连接到MySQL数据库再执行,对于一些批处理脚本,这种方式尤其方便。
示例:
mysql -uroot -p2143 db01 -e "select * from tb_book";
mysqladmin 是一个执行管理操作的客户端程序。可以用它来检查服务器的配置和当前状态、创建并删除数据库等。
可以通过 : mysqladmin --help 指令查看帮助文档
示例 :
mysqladmin -uroot -p2143 create 'test01';
mysqladmin -uroot -p2143 drop 'test01';
mysqladmin -uroot -p2143 version;
由于服务器生成的二进制日志文件以二进制格式保存,所以如果想要检查这些文本的文本格式,就会使用到mysqlbinlog 日志管理工具。
语法 :
mysqlbinlog [options] log-files1 log-files2 ...
选项:
-d, --database=name : 指定数据库名称,只列出指定的数据库相关操作。
-o, --offset=# : 忽略掉日志中的前n行命令。
-r,--result-file=name : 将输出的文本格式日志输出到指定文件。
-s, --short-form : 显示简单格式, 省略掉一些信息。
--start-datatime=date1 --stop-datetime=date2 : 指定日期间隔内的所有日志。
--start-position=pos1 --stop-position=pos2 : 指定位置间隔内的所有日志。
mysqldump 客户端工具用来备份数据库或在不同数据库之间进行数据迁移。备份内容包含创建表,及插入表的SQL语句。
语法 :
mysqldump [options] db_name [tables]
mysqldump [options] --database/-B db1 [db2 db3...]
mysqldump [options] --all-databases/-A
参数 :
-u, --user=name 指定用户名
-p, --password[=name] 指定密码
-h, --host=name 指定服务器IP或域名
-P, --port=# 指定连接端口
参数:
--add-drop-database 在每个数据库创建语句前加上 Drop database 语句
--add-drop-table 在每个表创建语句前加上 Drop table 语句 , 默认开启 ; 不开启 (--skip-add-drop-table)
-n, --no-create-db 不包含数据库的创建语句
-t, --no-create-info 不包含数据表的创建语句
-d --no-data 不包含数据
-T, --tab=name 自动生成两个文件:一个.sql文件,创建表结构的语句;
一个.txt文件,数据文件,相当于select into outfile
示例 :
mysqldump -uroot -p2143 db01 tb_book --add-drop-database --add-drop-table > a
mysqldump -uroot -p2143 -T /tmp test city
mysqlimport 是客户端数据导入工具,用来导入mysqldump 加 -T 参数后导出的文本文件。
语法:
参数 :
-u, --user=name 指定用户名
-p, --password[=name] 指定密码
-h, --host=name 指定服务器IP或域名
-P, --port=# 指定连接端口
示例 :
mysql -h 127.0.0.1 -P 3306 -u root -p
mysql -h127.0.0.1 -P3306 -uroot -p2143
0示例:
参数 :
-u, --user=name 指定用户名
-p, --password[=name] 指定密码
-h, --host=name 指定服务器IP或域名
-P, --port=# 指定连接端口
示例 :
mysql -h 127.0.0.1 -P 3306 -u root -p
mysql -h127.0.0.1 -P3306 -uroot -p2143
1如果需要导入sql文件,可以使用mysql中的source 指令 :
参数 :
-u, --user=name 指定用户名
-p, --password[=name] 指定密码
-h, --host=name 指定服务器IP或域名
-P, --port=# 指定连接端口
示例 :
mysql -h 127.0.0.1 -P 3306 -u root -p
mysql -h127.0.0.1 -P3306 -uroot -p2143
2mysqlshow 客户端对象查找工具,用来很快地查找存在哪些数据库、数据库中的表、表中的列或者索引。
语法:
参数 :
-u, --user=name 指定用户名
-p, --password[=name] 指定密码
-h, --host=name 指定服务器IP或域名
-P, --port=# 指定连接端口
示例 :
mysql -h 127.0.0.1 -P 3306 -u root -p
mysql -h127.0.0.1 -P3306 -uroot -p2143
3参数:
参数 :
-u, --user=name 指定用户名
-p, --password[=name] 指定密码
-h, --host=name 指定服务器IP或域名
-P, --port=# 指定连接端口
示例 :
mysql -h 127.0.0.1 -P 3306 -u root -p
mysql -h127.0.0.1 -P3306 -uroot -p2143
4示例:
参数 :
-u, --user=name 指定用户名
-p, --password[=name] 指定密码
-h, --host=name 指定服务器IP或域名
-P, --port=# 指定连接端口
示例 :
mysql -h 127.0.0.1 -P 3306 -u root -p
mysql -h127.0.0.1 -P3306 -uroot -p2143
5在任何一种数据库中,都会有各种各样的日志,记录着数据库工作的方方面面,以帮助数据库管理员追踪数据库曾经发生过的各种事件。MySQL 也不例外,在 MySQL 中,有 4 种不同的日志,分别是错误日志、二进制日志(BINLOG 日志)、查询日志和慢查询日志,这些日志记录着数据库在不同方面的踪迹。
错误日志是 MySQL 中最重要的日志之一,它记录了当 mysqld 启动和停止时,以及服务器在运行过程中发生任何严重错误时的相关信息。当数据库出现任何故障导致无法正常使用时,可以首先查看此日志。
该日志是默认开启的 , 默认存放目录为 mysql 的数据目录(var/lib/mysql), 默认的日志文件名为 hostname.err(hostname是主机名)。
查看日志位置指令 :
参数 :
-u, --user=name 指定用户名
-p, --password[=name] 指定密码
-h, --host=name 指定服务器IP或域名
-P, --port=# 指定连接端口
示例 :
mysql -h 127.0.0.1 -P 3306 -u root -p
mysql -h127.0.0.1 -P3306 -uroot -p2143
6
查看日志内容 :
参数 :
-u, --user=name 指定用户名
-p, --password[=name] 指定密码
-h, --host=name 指定服务器IP或域名
-P, --port=# 指定连接端口
示例 :
mysql -h 127.0.0.1 -P 3306 -u root -p
mysql -h127.0.0.1 -P3306 -uroot -p2143
7
二进制日志(BINLOG)记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但是不包括数据查询语句。此日志对于灾难时的数据恢复起着极其重要的作用,MySQL的主从复制, 就是通过该binlog实现的。
二进制日志,默认情况下是没有开启的,需要到MySQL的配置文件中开启,并配置MySQL日志的格式。
配置文件位置 : /usr/my.cnf
日志存放位置 : 配置时,给定了文件名但是没有指定路径,日志默认写入Mysql的数据目录。
参数 :
-u, --user=name 指定用户名
-p, --password[=name] 指定密码
-h, --host=name 指定服务器IP或域名
-P, --port=# 指定连接端口
示例 :
mysql -h 127.0.0.1 -P 3306 -u root -p
mysql -h127.0.0.1 -P3306 -uroot -p2143
8STATEMENT
该日志格式在日志文件中记录的都是SQL语句(statement),每一条对数据进行修改的SQL都会记录在日志文件中,通过Mysql提供的mysqlbinlog工具,可以清晰的查看到每条语句的文本。主从复制的时候,从库(slave)会将日志解析为原文本,并在从库重新执行一次。
ROW
该日志格式在日志文件中记录的是每一行的数据变更,而不是记录SQL语句。比如,执行SQL语句 : update tb_book set status='1' , 如果是STATEMENT 日志格式,在日志中会记录一行SQL文件; 如果是ROW,由于是对全表进行更新,也就是每一行记录都会发生变更,ROW 格式的日志中会记录每一行的数据变更。
MIXED
这是目前MySQL默认的日志格式,即混合了STATEMENT 和 ROW两种格式。默认情况下采用STATEMENT,但是在一些特殊情况下采用ROW来进行记录。MIXED 格式能尽量利用两种模式的优点,而避开他们的缺点。
由于日志以二进制方式存储,不能直接读取,需要用mysqlbinlog工具来查看,语法如下 :
参数 :
-u, --user=name 指定用户名
-p, --password[=name] 指定密码
-h, --host=name 指定服务器IP或域名
-P, --port=# 指定连接端口
示例 :
mysql -h 127.0.0.1 -P 3306 -u root -p
mysql -h127.0.0.1 -P3306 -uroot -p2143
9查看STATEMENT格式日志
执行插入语句 :
-e, --execute=name 执行SQL语句并退出
0查看日志文件 :

mysqlbin.index : 该文件是日志索引文件 , 记录日志的文件名;
mysqlbing.000001 :日志文件
查看日志内容 :
-e, --execute=name 执行SQL语句并退出
1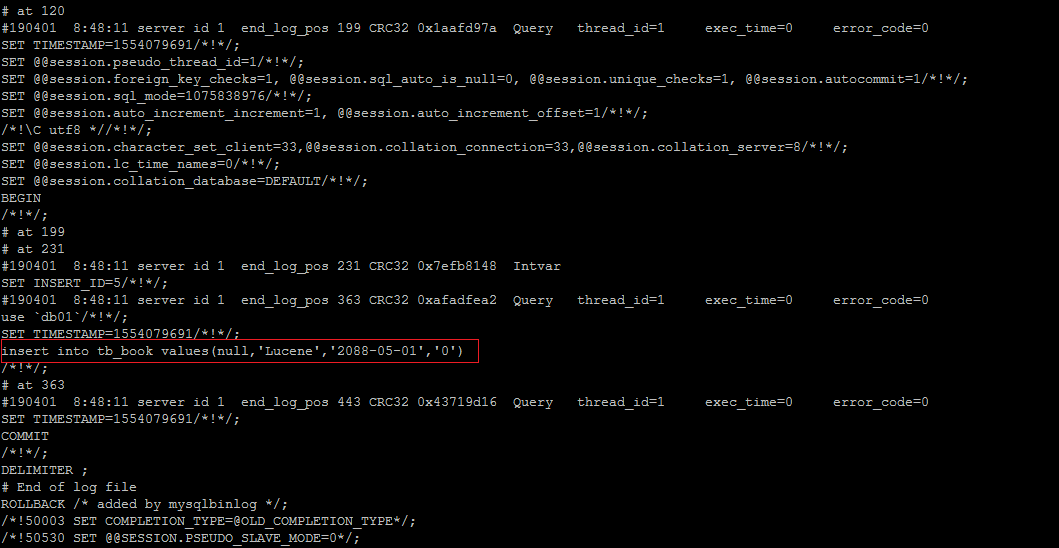
查看ROW格式日志
配置 :
-e, --execute=name 执行SQL语句并退出
2插入数据 :
-e, --execute=name 执行SQL语句并退出
3如果日志格式是 ROW , 直接查看数据 , 是查看不懂的 ; 可以在mysqlbinlog 后面加上参数 -vv
-e, --execute=name 执行SQL语句并退出
4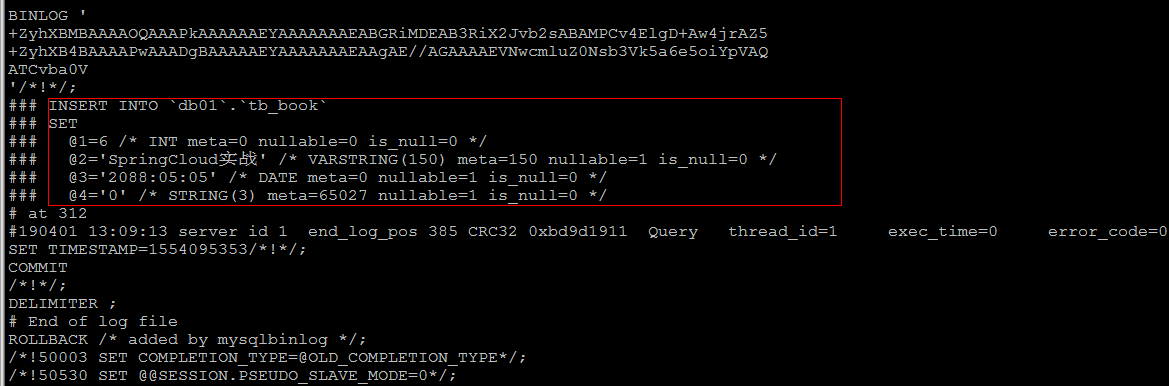
对于比较繁忙的系统,由于每天生成日志量大 ,这些日志如果长时间不清楚,将会占用大量的磁盘空间。下面我们将会讲解几种删除日志的常见方法 :
方式一
通过 Reset Master 指令删除全部 binlog 日志,删除之后,日志编号,将从 xxxx.000001重新开始 。
查询之前 ,先查询下日志文件 :

执行删除日志指令:
-e, --execute=name 执行SQL语句并退出
5执行之后, 查看日志文件 :

方式二
执行指令 purge master logs to 'mysqlbin.******' ,该命令将删除 ****** 编号之前的所有日志。
方式三
执行指令 purge master logs before 'yyyy-mm-dd hh24:mi:ss' ,该命令将删除日志为 "yyyy-mm-dd hh24:mi:ss" 之前产生的所有日志 。
方式四
设置参数 --expire_logs_days=# ,此参数的含义是设置日志的过期天数, 过了指定的天数后日志将会被自动删除,这样将有利于减少DBA 管理日志的工作量。
配置如下 :

查询日志中记录了客户端的所有操作语句,而二进制日志不包含查询数据的SQL语句。
默认情况下, 查询日志是未开启的。如果需要开启查询日志,可以设置以下配置 :
-e, --execute=name 执行SQL语句并退出
6在 mysql 的配置文件 /usr/my.cnf 中配置如下内容 :

配置完毕之后,在数据库执行以下操作 :
-e, --execute=name 执行SQL语句并退出
7执行完毕之后, 再次来查询日志文件 :
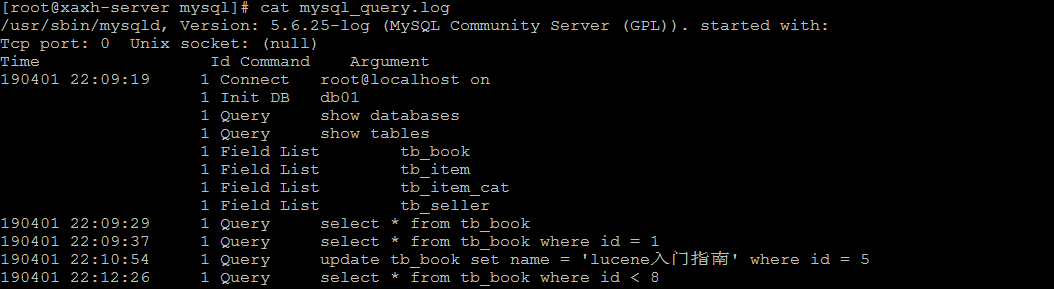
慢查询日志记录了所有执行时间超过参数 long_query_time 设置值并且扫描记录数不小于 min_examined_row_limit 的所有的SQL语句的日志。long_query_time 默认为 10 秒,最小为 0, 精度可以到微秒。
慢查询日志默认是关闭的 。可以通过两个参数来控制慢查询日志 :
-e, --execute=name 执行SQL语句并退出
8和错误日志、查询日志一样,慢查询日志记录的格式也是纯文本,可以被直接读取。
1) 查询long_query_time 的值。

2) 执行查询操作
-e, --execute=name 执行SQL语句并退出
9
由于该语句执行时间很短,为0s , 所以不会记录在慢查询日志中。
示例:
mysql -uroot -p2143 db01 -e "select * from tb_book";
0
该SQL语句 , 执行时长为 26.77s ,超过10s , 所以会记录在慢查询日志文件中。
3) 查看慢查询日志文件
直接通过cat 指令查询该日志文件 :

如果慢查询日志内容很多, 直接查看文件,比较麻烦, 这个时候可以借助于mysql自带的 mysqldumpslow 工具, 来对慢查询日志进行分类汇总。

复制是指将主数据库的DDL 和 DML 操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。
MySQL支持一台主库同时向多台从库进行复制, 从库同时也可以作为其他从服务器的主库,实现链状复制。
MySQL 的主从复制原理如下。
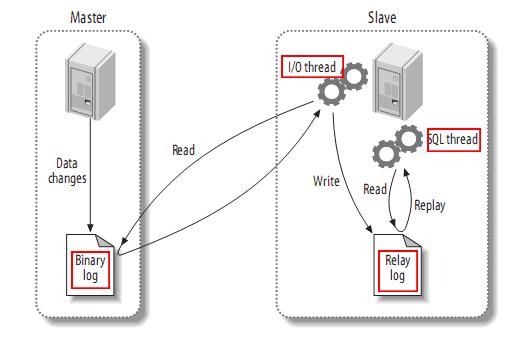
从上层来看,复制分成三步:
Master 主库在事务提交时,会把数据变更作为时间 Events 记录在二进制日志文件 Binlog 中。
主库推送二进制日志文件 Binlog 中的日志事件到从库的中继日志 Relay Log 。
slave重做中继日志中的事件,将改变反映它自己的数据。
MySQL 复制的有点主要包含以下三个方面:
主库出现问题,可以快速切换到从库提供服务。
可以在从库上执行查询操作,从主库中更新,实现读写分离,降低主库的访问压力。
可以在从库中执行备份,以避免备份期间影响主库的服务。
1) 在master 的配置文件(/usr/my.cnf)中,配置如下内容:
示例:
mysql -uroot -p2143 db01 -e "select * from tb_book";
12) 执行完毕之后,需要重启Mysql:
示例:
mysql -uroot -p2143 db01 -e "select * from tb_book";
23) 创建同步数据的账户,并且进行授权操作:
示例:
mysql -uroot -p2143 db01 -e "select * from tb_book";
34) 查看master状态:
示例:
mysql -uroot -p2143 db01 -e "select * from tb_book";
4
字段含义:
示例:
mysql -uroot -p2143 db01 -e "select * from tb_book";
51) 在 slave 端配置文件中,配置如下内容:
示例:
mysql -uroot -p2143 db01 -e "select * from tb_book";
62) 执行完毕之后,需要重启Mysql:
示例:
mysql -uroot -p2143 db01 -e "select * from tb_book";
73) 执行如下指令 :
示例:
mysql -uroot -p2143 db01 -e "select * from tb_book";
8指定当前从库对应的主库的IP地址,用户名,密码,从哪个日志文件开始的那个位置开始同步推送日志。
4) 开启同步操作
示例:
mysql -uroot -p2143 db01 -e "select * from tb_book";
9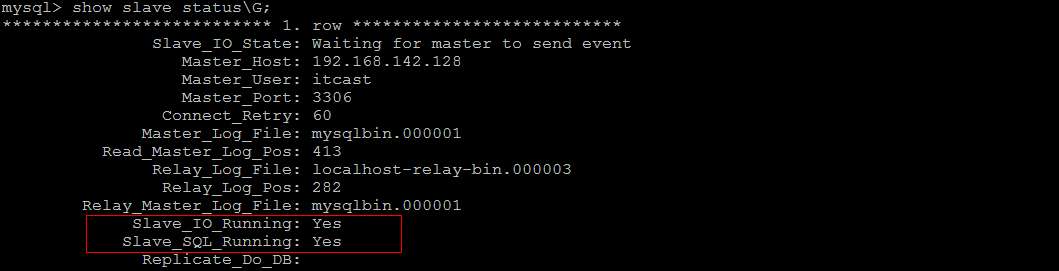
5) 停止同步操作
示例 :
mysqladmin -uroot -p2143 create 'test01';
mysqladmin -uroot -p2143 drop 'test01';
mysqladmin -uroot -p2143 version;
01) 在主库中创建数据库,创建表,并插入数据 :
示例 :
mysqladmin -uroot -p2143 create 'test01';
mysqladmin -uroot -p2143 drop 'test01';
mysqladmin -uroot -p2143 version;
12) 在从库中查询数据,进行验证 :
在从库中,可以查看到刚才创建的数据库:

在该数据库中,查询user表中的数据:

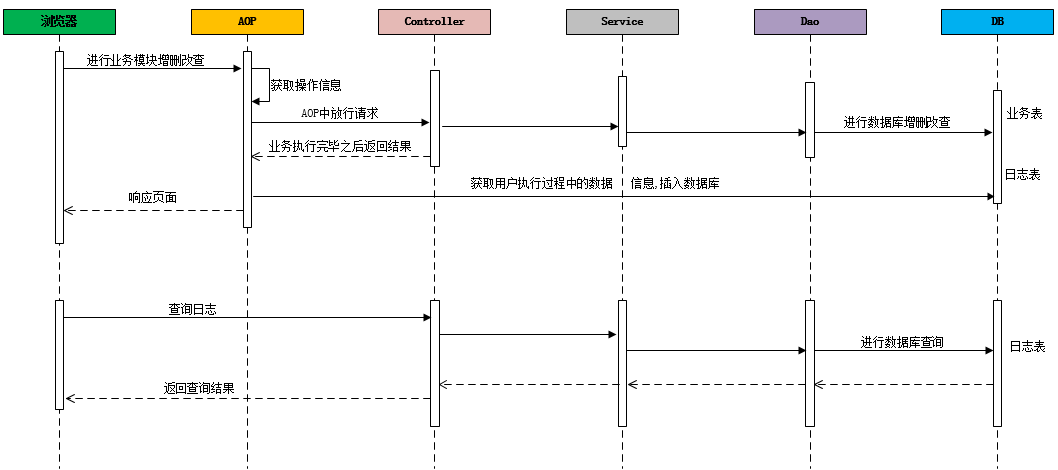
在业务系统中,需要记录当前业务系统的访问日志,该访问日志包含:操作人,操作时间,访问类,访问方法,请求参数,请求结果,请求结果类型,请求时长 等信息。记录详细的系统访问日志,主要便于对系统中的用户请求进行追踪,并且在系统 的管理后台可以查看到用户的访问记录。
记录系统中的日志信息,可以通过Spring 框架的AOP来实现。具体的请求处理流程,如下:
示例 :
mysqladmin -uroot -p2143 create 'test01';
mysqladmin -uroot -p2143 drop 'test01';
mysqladmin -uroot -p2143 version;
2示例 :
mysqladmin -uroot -p2143 create 'test01';
mysqladmin -uroot -p2143 drop 'test01';
mysqladmin -uroot -p2143 version;
3示例 :
mysqladmin -uroot -p2143 create 'test01';
mysqladmin -uroot -p2143 drop 'test01';
mysqladmin -uroot -p2143 version;
4示例 :
mysqladmin -uroot -p2143 create 'test01';
mysqladmin -uroot -p2143 drop 'test01';
mysqladmin -uroot -p2143 version;
5示例 :
mysqladmin -uroot -p2143 create 'test01';
mysqladmin -uroot -p2143 drop 'test01';
mysqladmin -uroot -p2143 version;
6示例 :
mysqladmin -uroot -p2143 create 'test01';
mysqladmin -uroot -p2143 drop 'test01';
mysqladmin -uroot -p2143 version;
7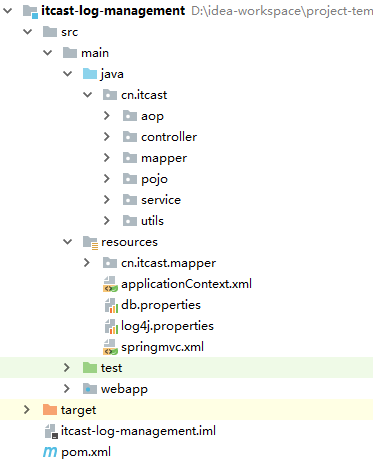
通过自定义注解,来标示方法需不需要进行记录日志,如果该方法在访问时需要记录日志,则在该方法上标示该注解既可。
示例 :
mysqladmin -uroot -p2143 create 'test01';
mysqladmin -uroot -p2143 drop 'test01';
mysqladmin -uroot -p2143 version;
8示例 :
mysqladmin -uroot -p2143 create 'test01';
mysqladmin -uroot -p2143 drop 'test01';
mysqladmin -uroot -p2143 version;
9在需要记录日志的方法上加上注解@OperateLog。
mysqlbinlog [options] log-files1 log-files2 ...
选项:
-d, --database=name : 指定数据库名称,只列出指定的数据库相关操作。
-o, --offset=# : 忽略掉日志中的前n行命令。
-r,--result-file=name : 将输出的文本格式日志输出到指定文件。
-s, --short-form : 显示简单格式, 省略掉一些信息。
--start-datatime=date1 --stop-datetime=date2 : 指定日期间隔内的所有日志。
--start-position=pos1 --stop-position=pos2 : 指定位置间隔内的所有日志。
0mysqlbinlog [options] log-files1 log-files2 ...
选项:
-d, --database=name : 指定数据库名称,只列出指定的数据库相关操作。
-o, --offset=# : 忽略掉日志中的前n行命令。
-r,--result-file=name : 将输出的文本格式日志输出到指定文件。
-s, --short-form : 显示简单格式, 省略掉一些信息。
--start-datatime=date1 --stop-datetime=date2 : 指定日期间隔内的所有日志。
--start-position=pos1 --stop-position=pos2 : 指定位置间隔内的所有日志。
1mysqlbinlog [options] log-files1 log-files2 ...
选项:
-d, --database=name : 指定数据库名称,只列出指定的数据库相关操作。
-o, --offset=# : 忽略掉日志中的前n行命令。
-r,--result-file=name : 将输出的文本格式日志输出到指定文件。
-s, --short-form : 显示简单格式, 省略掉一些信息。
--start-datatime=date1 --stop-datetime=date2 : 指定日期间隔内的所有日志。
--start-position=pos1 --stop-position=pos2 : 指定位置间隔内的所有日志。
2mysqlbinlog [options] log-files1 log-files2 ...
选项:
-d, --database=name : 指定数据库名称,只列出指定的数据库相关操作。
-o, --offset=# : 忽略掉日志中的前n行命令。
-r,--result-file=name : 将输出的文本格式日志输出到指定文件。
-s, --short-form : 显示简单格式, 省略掉一些信息。
--start-datatime=date1 --stop-datetime=date2 : 指定日期间隔内的所有日志。
--start-position=pos1 --stop-position=pos2 : 指定位置间隔内的所有日志。
3mysqlbinlog [options] log-files1 log-files2 ...
选项:
-d, --database=name : 指定数据库名称,只列出指定的数据库相关操作。
-o, --offset=# : 忽略掉日志中的前n行命令。
-r,--result-file=name : 将输出的文本格式日志输出到指定文件。
-s, --short-form : 显示简单格式, 省略掉一些信息。
--start-datatime=date1 --stop-datetime=date2 : 指定日期间隔内的所有日志。
--start-position=pos1 --stop-position=pos2 : 指定位置间隔内的所有日志。
4前端代码使用 Bootstrap + AdminLTE 进行布局, 使用Vuejs 进行视图层展示。
mysqlbinlog [options] log-files1 log-files2 ...
选项:
-d, --database=name : 指定数据库名称,只列出指定的数据库相关操作。
-o, --offset=# : 忽略掉日志中的前n行命令。
-r,--result-file=name : 将输出的文本格式日志输出到指定文件。
-s, --short-form : 显示简单格式, 省略掉一些信息。
--start-datatime=date1 --stop-datetime=date2 : 指定日期间隔内的所有日志。
--start-position=pos1 --stop-position=pos2 : 指定位置间隔内的所有日志。
5mysqlbinlog [options] log-files1 log-files2 ...
选项:
-d, --database=name : 指定数据库名称,只列出指定的数据库相关操作。
-o, --offset=# : 忽略掉日志中的前n行命令。
-r,--result-file=name : 将输出的文本格式日志输出到指定文件。
-s, --short-form : 显示简单格式, 省略掉一些信息。
--start-datatime=date1 --stop-datetime=date2 : 指定日期间隔内的所有日志。
--start-position=pos1 --stop-position=pos2 : 指定位置间隔内的所有日志。
64.5.3 分页插件
mysqlbinlog [options] log-files1 log-files2 ...
选项:
-d, --database=name : 指定数据库名称,只列出指定的数据库相关操作。
-o, --offset=# : 忽略掉日志中的前n行命令。
-r,--result-file=name : 将输出的文本格式日志输出到指定文件。
-s, --short-form : 显示简单格式, 省略掉一些信息。
--start-datatime=date1 --stop-datetime=date2 : 指定日期间隔内的所有日志。
--start-position=pos1 --stop-position=pos2 : 指定位置间隔内的所有日志。
7可以通过postman来访问业务系统,再查看数据库中的日志信息,验证能不能将用户的访问日志记录下来。
系统中用户访问日志的数据量,随着时间的推移,这张表的数据量会越来越大,因此我们需要根据业务需求,来对日志查询模块的性能进行优化。
1) 分页查询优化
由于在进行日志查询时,是进行分页查询,那也就意味着,在查看时,至少需要查询两次:
A. 查询符合条件的总记录数。--> count 操作
B. 查询符合条件的列表数据。--> 分页查询 limit 操作
通常来说,count() 都需要扫描大量的行(意味着需要访问大量的数据)才能获得精确的结果,因此是很难对该SQL进行优化操作的。如果需要对count进行优化,可以采用另外一种思路,可以增加汇总表,或者Redis缓存来专门记录该表对应的记录数,这样的话,就可以很轻松的实现汇总数据的查询,而且效率很高,但是这种统计并不能保证百分之百的准确 。对于数据库的操作,“快速、精确、实现简单”,三者永远只能满足其二,必须舍掉其中一个。
2) 条件查询优化
针对于条件查询,需要对查询条件,及排序字段建立索引。
3) 读写分离
通过主从复制集群,来完成读写分离,使写操作走主节点, 而读操作,走从节点。
4) MySQL服务器优化
5) 应用优化
创建一张表用来记录日志表的总数据量:
mysqlbinlog [options] log-files1 log-files2 ...
选项:
-d, --database=name : 指定数据库名称,只列出指定的数据库相关操作。
-o, --offset=# : 忽略掉日志中的前n行命令。
-r,--result-file=name : 将输出的文本格式日志输出到指定文件。
-s, --short-form : 显示简单格式, 省略掉一些信息。
--start-datatime=date1 --stop-datetime=date2 : 指定日期间隔内的所有日志。
--start-position=pos1 --stop-position=pos2 : 指定位置间隔内的所有日志。
8在每次插入数据之后,更新该表 :
mysqlbinlog [options] log-files1 log-files2 ...
选项:
-d, --database=name : 指定数据库名称,只列出指定的数据库相关操作。
-o, --offset=# : 忽略掉日志中的前n行命令。
-r,--result-file=name : 将输出的文本格式日志输出到指定文件。
-s, --short-form : 显示简单格式, 省略掉一些信息。
--start-datatime=date1 --stop-datetime=date2 : 指定日期间隔内的所有日志。
--start-position=pos1 --stop-position=pos2 : 指定位置间隔内的所有日志。
9在进行分页查询时, 获取总记录数,从该表中查询既可。
mysqldump [options] db_name [tables]
mysqldump [options] --database/-B db1 [db2 db3...]
mysqldump [options] --all-databases/-A
0在进行分页时,一般通过创建覆盖索引,能够比较好的提高性能。一个非常常见,而又非常头疼的分页场景就是 "limit 1000000,10" ,此时MySQL需要搜索出前1000010 条记录后,仅仅需要返回第 1000001 到 1000010 条记录,前1000000 记录会被抛弃,查询代价非常大。
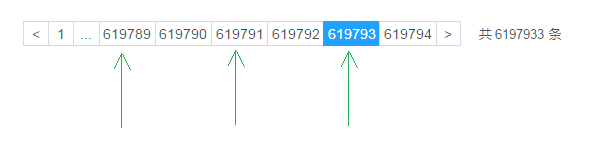
当点击比较靠后的页码时,就会出现这个问题,查询效率非常慢。
优化SQL:
mysqldump [options] db_name [tables]
mysqldump [options] --database/-B db1 [db2 db3...]
mysqldump [options] --all-databases/-A
1将上述SQL优化为 :
mysqldump [options] db_name [tables]
mysqldump [options] --database/-B db1 [db2 db3...]
mysqldump [options] --all-databases/-A
2mysqldump [options] db_name [tables]
mysqldump [options] --database/-B db1 [db2 db3...]
mysqldump [options] --all-databases/-A
3
当根据操作人进行查询时, 查询的效率很低,耗时比较长。原因就是因为在创建数据库表结构时,并没有针对于 操作人 字段建立索引。
mysqldump [options] db_name [tables]
mysqldump [options] --database/-B db1 [db2 db3...]
mysqldump [options] --all-databases/-A
4同上 , 为了查询效率高,我们也需要对 操作方法、返回值类型、操作耗时 等字段进行创建索引,以提高查询效率。
mysqldump [options] db_name [tables]
mysqldump [options] --database/-B db1 [db2 db3...]
mysqldump [options] --all-databases/-A
5在查询数据时,如果业务需求中需要我们对结果内容进行了排序处理 , 这个时候,我们还需要对排序的字段建立适当的索引, 来提高排序的效率 。
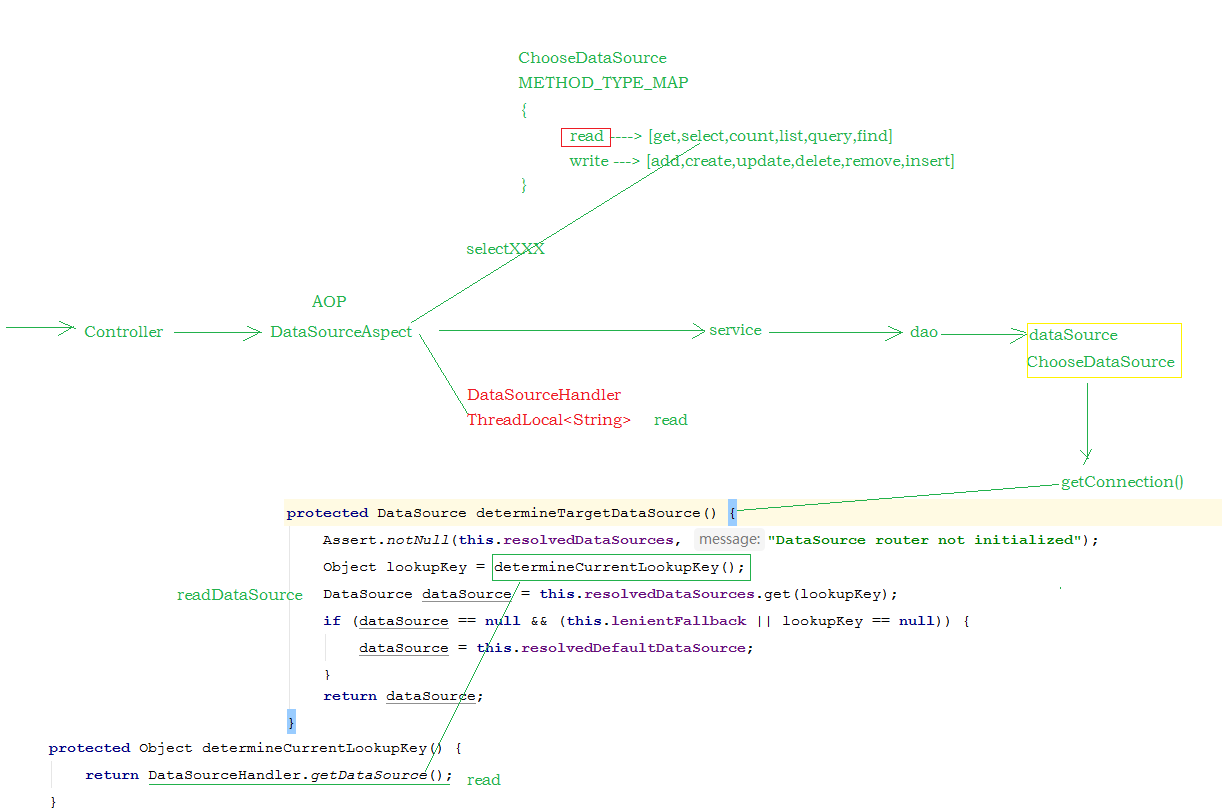
在Mysql主从复制的基础上,可以使用读写分离来降低单台Mysql节点的压力,从而来提高访问效率,读写分离的架构如下:
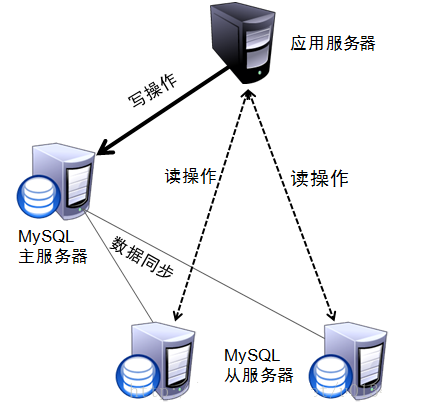
对于读写分离的实现,可以通过Spring AOP 来进行动态的切换数据源,进行操作 :
db.properties
mysqldump [options] db_name [tables]
mysqldump [options] --database/-B db1 [db2 db3...]
mysqldump [options] --all-databases/-A
6applicationContext-datasource.xml
mysqldump [options] db_name [tables]
mysqldump [options] --database/-B db1 [db2 db3...]
mysqldump [options] --all-databases/-A
7ChooseDataSource
mysqldump [options] db_name [tables]
mysqldump [options] --database/-B db1 [db2 db3...]
mysqldump [options] --all-databases/-A
8DataSourceHandler
mysqldump [options] db_name [tables]
mysqldump [options] --database/-B db1 [db2 db3...]
mysqldump [options] --all-databases/-A
9DataSourceAspect
参数 :
-u, --user=name 指定用户名
-p, --password[=name] 指定密码
-h, --host=name 指定服务器IP或域名
-P, --port=# 指定连接端口
0通过 @Order(-9999) 注解来控制事务管理器, 与该通知类的加载顺序 , 需要让通知类 , 先加载 , 来判定使用哪个数据源 .
在主库和从库中,执行如下SQL语句,来查看是否读的时候, 从从库中读取 ; 写入操作的时候,是否写入到主库。
参数 :
-u, --user=name 指定用户名
-p, --password[=name] 指定密码
-h, --host=name 指定服务器IP或域名
-P, --port=# 指定连接端口
1
可以在业务系统中使用redis来做缓存,缓存一些基础性的数据,来降低关系型数据库的压力,提高访问效率。
如果业务系统中的数据量比较大(达到千万级别),这个时候,如果再对数据库进行查询,特别是进行分页查询,速度将变得很慢(因为在分页时首先需要count求合计数),为了提高访问效率,这个时候,可以考虑加入Solr 或者 ElasticSearch全文检索服务,来提高访问效率。
也可以考虑将非核心(重要)数据,存在 MongoDB 中,这样可以提高插入以及查询的效率。